With the respective lockdowns and flatlining on home HIIT workouts (rocked a backpack with books for a while as weight!), it was time for a change. It was time to invest in a home gym setup. Here is what we are rocking which as contributed to an increase in muscle mass and a decrease in body fat among other benefits.
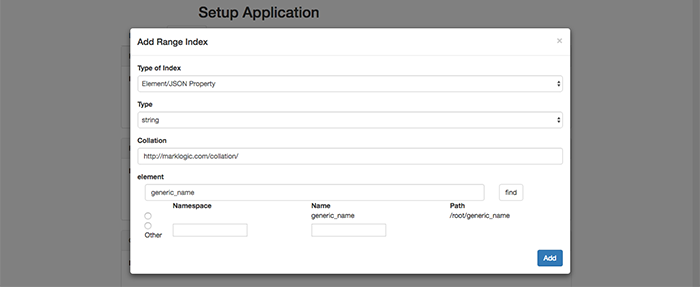
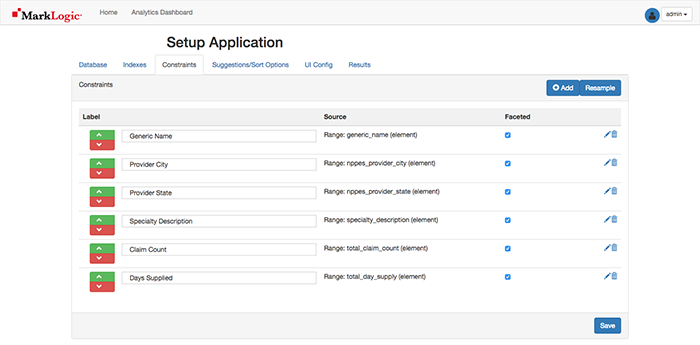
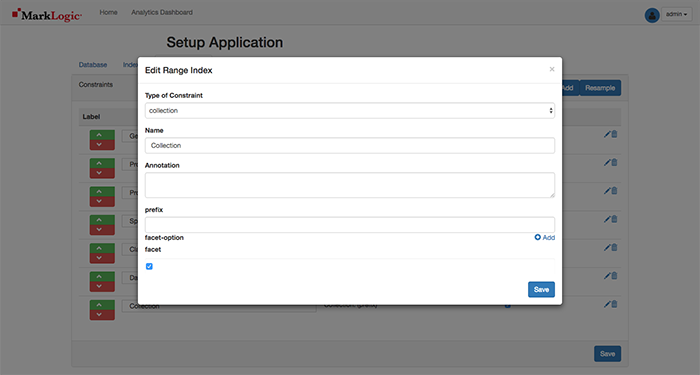
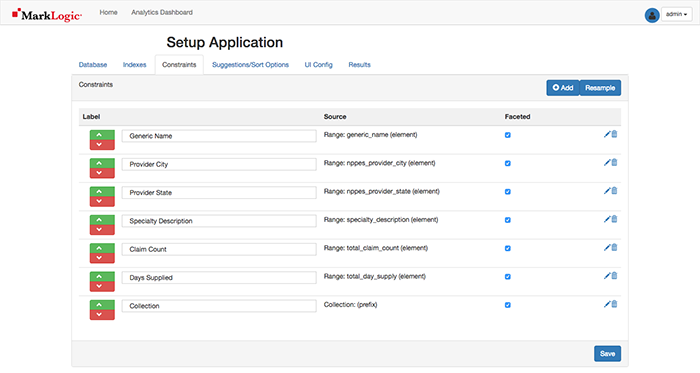
1. Get a scale
Without measurement, it is near impossible to know how you are doing. The old trusty one purchased for $30 a few years ago decided to start flashing all sorts of error messages so it was definitely time for an upgrade. Picked up the Withings Body + which has been amazing in keeping the measurements and analysis of where we stand. That’s right, the Body+ syncs the details up to the cloud and you can view a dashboard of details on the app. Those pizzas and holiday treats add up (3-5lbs by the day after actually!), and so this pushes you to work harder and burn those off to get back to where you want to be!
2. Weights
You could go out and buy weights piecemeal although that takes up a lot of space in your place and also time tracking down the respective weights (in lbs) that you need. Stalked PowerBlock Elite Series Dumbells (would personally call them SMART BELLS) like it was a 2nd job. Or, rather, followed them on Insta/Twitter and set alerts for availability to buy them as soon as they went on-sale very similar to buying a ticket immediately after the on-sale for a festival. Pick-up the additional weight add-ons even if you are not sure you will need them, it will help the resale later if you decide to start hitting the gym instead.
Looking for something more price reasonable? The CAP Adjustable Barbells look good and are not very expensive. Have heard that Bowflex is another good alternative although, at that price point, you mind as well spend a few extra and go for the PowerBlocks.
3. TRX
The TRX Home2 System is a solid bundle enabling you to train ANYWHERE. It includes an over-the-door anchor so there’s no need to mount a hook or anchor in the living room although by all means go for it if that’s your home aesthetic. Recommend adding on the TRX Exercise Bands Package (~$15) to this purchase to get the most out of the shipping cost for an item you’ll want anyway. Planning to take this outside to the back deck (attached to a hook with some rope) or even the park (attached to a tree) once the weather warms up!
4. Bands
Bands are very handy for building strength. And the TRX Exercise Bands Package (~$15) are a bundle that enable you to work your way up over time. Lots of uses for them: Internal/External Rotations and Banded Walks to name a few.
5. A versatile space-saving workout bench
If it is not already obvious, the key theme here is “don’t take up a lot of space.” The Power Systems Deck which is very versatile yet easily stowed away. Highly recommend!
6. Workout Mat
Yo Gorilla Mat for the win. Went with the 8′ x 4′ version and never looked back. This thing is like an instant gym floor in your places for workouts. It also rolls up and slides into a bag for stowage. Space-saving is always a win. It smelled funky at first although over time that has chilled out with use. The package included a towel of sorts, still not sure what that’s used for and, who cares, the mat is awesome!
7. Slides
Wanna do pikes, mountain climbers, wipeouts, etc without burning through your socks or using a towel? Slidez are the answer! Slides enable all sorts of awesome and challenging exercises delivering lots of value!
8. Foam Roller
Forget foam, Triggerpoint is the way to go. The plastic innertube limits any “give” that the foam ones suffer from. Have had one for 7 years so it’s no surprise this is consistently rated as a top roller. Fun fact: Swell Water Bottles make a good travel roller.
9. Theragun
Sometimes it’s nice to have more of an inactive roll or a self-massage. Theragun PRO to the rescue. With all sorts of programs that may be selected in the app which controls the device via bluetooth, this is the go-to. Ideally, you have a partner in your life and this can be one of your activities together. It is possible to self-massage with the Theragun (and it works out well!) although there are no doubt more benefits of fully resting during a massage.
10. Yoga Strap
The Manduka Yoga Strap is a big win with all the time spent sitting these days. One of the favorite exercises with it is the hamstring stretch for 30 seconds. From there: fold the opposite leg (allowing the upward leg to flex more), note the spot on the ceiling where you can flex that upward leg to, and try to keep that stretch for another 30 seconds after lowering the “opposite leg.” Repeat.
11. Yoga block (or 2!)
Foam blocks just never seemed that great due to their flimsiness. Cork to the rescue! The Manduka Cork Yoga Block stays true to form and does not give a millimeter. The benefits of blocks are underrated just like Savasana (still working on it!) yet they help you work deeper into areas in a safe way so that you are not straining yourself for the sake of the pose.
12. Resistance Bands
Eventually, some sort of the body will invariably become unhappy with the exercising or maybe you are not stretching as much as you should be. It happens! Working from home, there has been a lot of Rainbow Sandal wearing around here which has not made the ankles very happy. And so, some bands are needed. The Theraband Beginner Resistance Bands are the way to go for rehabilitation exercises.
13. Balance and Knee Pad
Speaking of the body getting “unhappy,” that can include the knees. And also, maybe you want to work on some balance exercises. Am still trying out some options here although have a foam pad on the way and will update with details.
These are all the respective home workout tools in the toolbox. Combined with a solid training program, there is no reason why you can’t get or stay fit during these crazy times. Plus, when the weights are starting at you (they have eyes!) and no commute to the gym necessary with all the associated packing of clothes etc, it is a lot harder to skip a workout and easier to make it happen.